We are not evaluating AI coding agents the way they are actually used
A problem with AI coding benchmarks
Whenever a new model drops from a major lab you can expect to see a table like this:
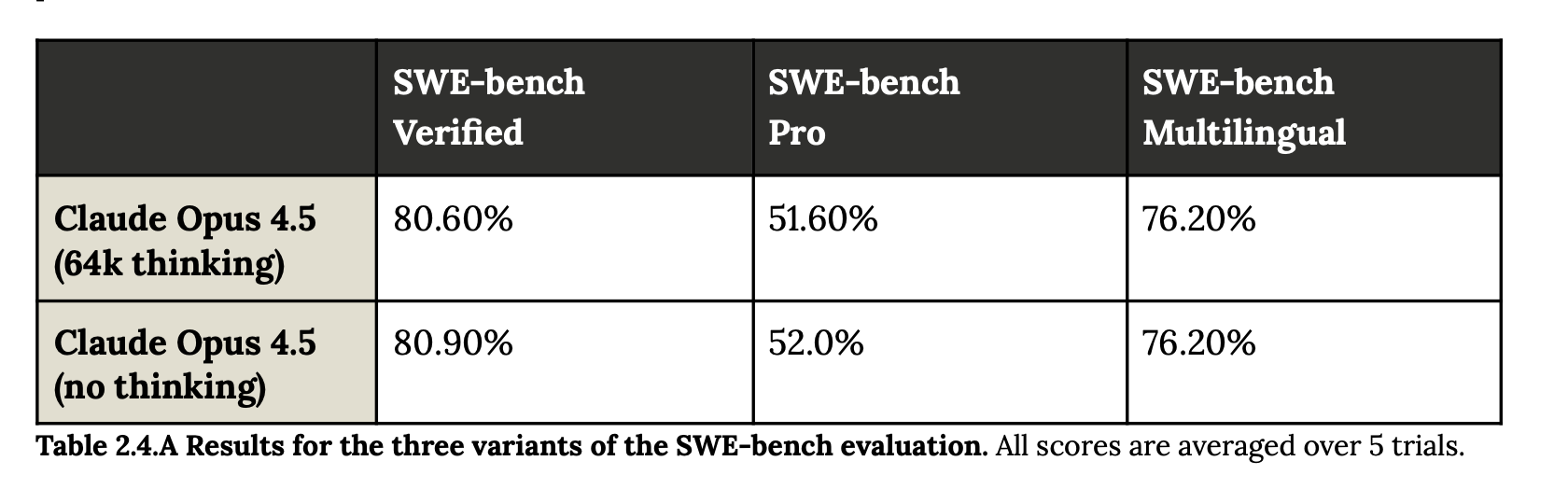
or a graph like this:
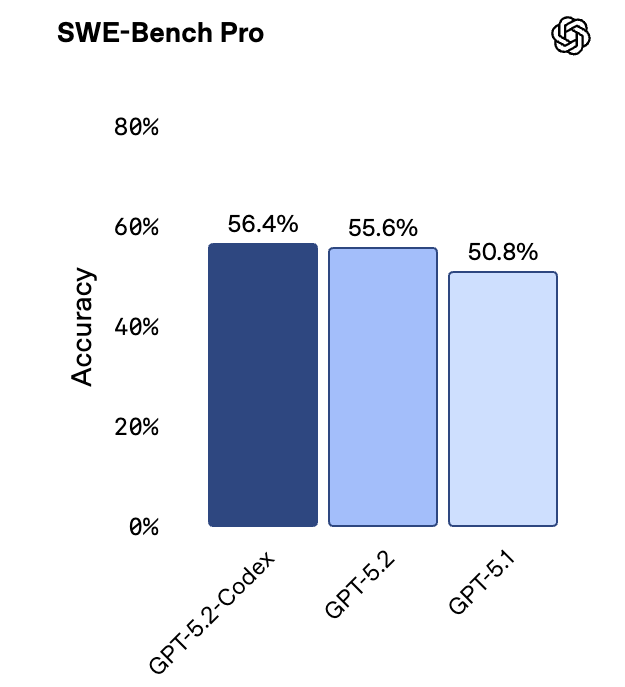
If you visit the official dashboards for benchmarks like SWE-Bench-Pro, you will see a graph like this:

(Side note: For a deep dive on what these SWE-Bench style benchmarks test for, see our blog post)
If you’ve been in this space across multiple model releases, you quickly notice a few patterns:
- Benchmark scores reported by frontier labs (OpenAI, Anthropic, etc.) are typically higher than the scores reported by the official benchmarks (e.g. SWE-Bench-Pro).
- Benchmark scores often do not align with vibes. Some models that feel better in real-world use score worse on benchmarks.
- Benchmarks are static. They are only evaluated once, and sometimes it feels like performance drops after launch.
There is one main reason that explains some of these patterns: Coding agents are not evaluated the same way they are used in real life. This applies both for benchmarks reported by the labs themselves, and by the official benchmark organizers.
The Evaluation / Real-World Usage Gaps
First of all, it helps to spell out how these models are used in the real-world.
- Models are now typically used in a scaffold or harness like Claude Code, Codex, Cursor, etc. Not as stand-alone models.
- Frontier labs release a few models per year, but they update their scaffolds much more often. Codex, for example, feels like it averages more than one release per week.
- Modern production coding agent scaffolds have powerful features that improve coding performance. For example, planning mode in Claude Code typically delivers better results than directly asking for implementation.
In comparison, here is how these models are evaluated by frontier labs and benchmark organizers, respectively.
How Benchmark Organizers Evaluate Coding Performance
There are official leaderboards for the SWE-Bench family, SWE-Bench Pro, Terminal-Bench, and many other benchmarks related to coding performance.
I find that these leaderboards are rarely helpful. They are typically outdated and do not use SOTA model configurations (e.g. do not use highest reasoning effort). In addition, they are evaluating models very differently from how they are used:
- Benchmark leaderboards typically run models on a standardized scaffold/harness.
- Standardized scaffolds are not as good as the scaffolds in Claude Code, Codex, etc. SWE-Bench, for example, uses the mini-SWE-Agent scaffold, which is 100-lines of Python.
- Benchmark leaderboards typically generate scores once and never update them. Model performance can change, for example due to bugs in the inference infrastructure.
The goal of official benchmarks is usually to evaluate models, not scaffolds. They want to understand what model performs best with a given, minimal scaffold.
How Frontier Labs Evaluate Coding Performance
The incentives for frontier labs are expectedly different. They want to report the best scores on a given benchmark. For this reason, frontier labs often run on sophisticated scaffolds with models tuned to the highest compute configurations. This is actually closer to the way these models are used in real life, but may go too far in the other direction of painting a picture that is overly-optimistic, since real developers have constraints on cost and runtime that will not be imposed on benchmarks.
In addition to this, another critical issue with frontier lab evaluations is that they are also just run once and never updated. As mentioned earlier, coding agent scaffolds like Claude Code and Codex are updated regularly, and these scaffold changes could impact model performance on evaluations, but these changes are not captured.
How we should evaluate AI coding agents
As a developer using these models in my job, the most important question I want answered is: What model + scaffold combination will give me the best results at a reasonable cost and runtime?
Should I use Claude Code with Opus 4.5, or Codex with gpt-5.2-codex-xhigh? Should I try out the new Antigravity IDE or stick with
Gemini CLI?
To answer these questions effectively, MarginLab runs evals on tools in exactly the way those tools are used in real life, and we update those evals regularly to reflect changes in scaffold versions. Check out our Claude Code Tracker, for example.
We are actively working on a number of other eval dashboards that follow the same philosophy. Please contact us if there are any specific ones you are interested in.